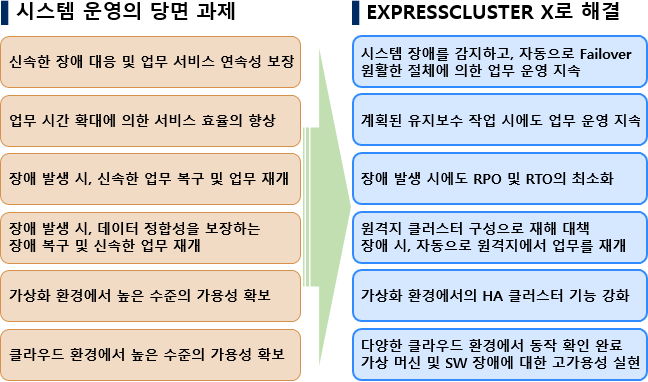
NEC EXPRESSCLUSTER ХЌЗЏНКХЭ ШАПы ЙцЙ§
HA ХЌЗЏНКХЭ
НУРх СЁРЏРВ
ШАПы ЙцЙ§
ДйОчЧб БИМК
Е№НКХЉ БИМК
ЕЅРЬХЭ ЙЬЗЏ
НУНКХл ПЌАш
ЁЁ
NEC HA ХЌЗЏНКХЭ
ЁЁ
ХЌЗЏНКХЭ НУРхСЁРЏРВ
ЁЁ
ХЌЗЏНКХЭ ШАПыЙцЙ§
ЁЁ
ДйОчЧб ХЌЗЏНКХЭ БИМК
ЁЁ
ХЌЗЏНКХЭ Е№НКХЉ БИМК
ЁЁ
ЕЅРЬХЭ ЙЬЗЏ БтДЩ
ЁЁ
ХИЛч НУНКХл ПЌАш
ЁЁ
ЕЕРд ЛчЗЪ
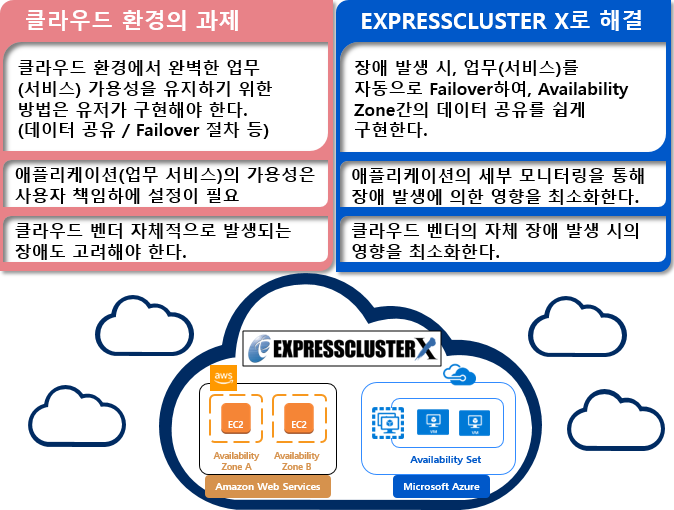
РхОж ЙпЛ§НУ ОїЙЋ(МКёНК) ПЌМгМК РЏСі
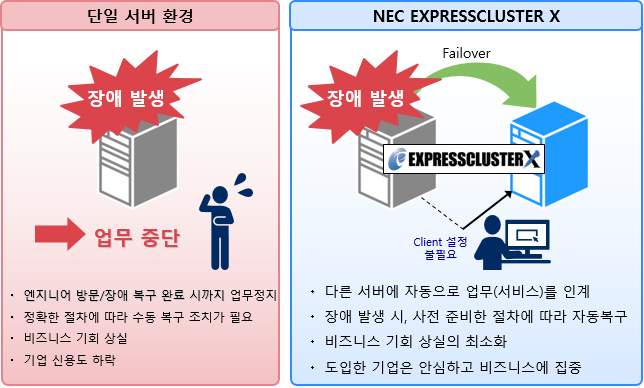
НУНКХл РхОжИІ СЄШЎЧЯАд АЈСіЧЯПЉ ОїЙЋМКёНКИІ РкЕПКЙБИ(Failover)
Ём ДмРЯ МЙі ШЏАц
- ПЃСіДЯОю ЙцЙЎ/РхОж КЙБИ ПЯЗс НУБюСі ОїЙЋСЄСі
- СЄШЎЧб Р§ТїПЁ ЕћЖѓ МіЕП КЙБИ СЖФЁАЁ ЧЪПф
- КёСюДЯНК БтШИ ЛѓНЧ
- БтОї НХПыЕЕ ЧЯЖє
Ём NEC EXPRESSCLUSTER X ШЏАц
- ДйИЅ МЙіПЁ РкЕПРИЗЮ ОїЙЋ(МКёНК)ИІ РЮАш
- РхОж ЙпЛ§ НУ, ЛчРќ СиКёЧб Р§ТїПЁ ЕћЖѓ РкЕПКЙБИ
- КёСюДЯНК БтШИ ЛѓНЧРЧ УжМвШ
- ЕЕРдЧб БтОїРК ОШНЩЧЯАэ КёСюДЯНКПЁ С§Сп
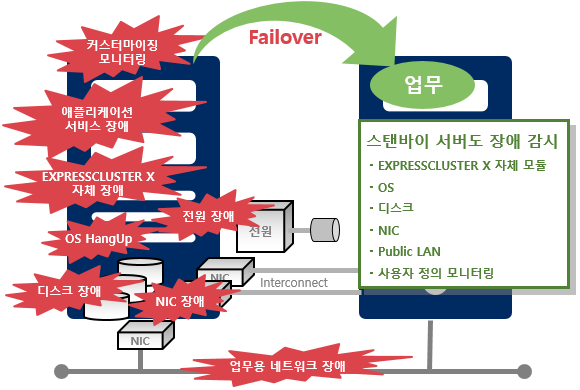
ДйОчЧб РхОжИІ АЈСіЧЯПЉ РкЕПРИЗЮ Failover
OS РхОж, DB РхОж Ею ДйОчЧб РхОжИІ АЈСіЧЯПЉ Failover НЧНУ
Ём ДйОчЧб РхОжИІ АЈСі
- ФПНКХЭИЖРЬТЁ И№ДЯХЭИЕ
- ОжЧУИЎФЩРЬМЧ МКёНК РхОж АЈНУ
- EXPRESSCLUSTER X РкУМ РхОж АЈНУ
- РќПј РхОж АЈНУ
- OS HangUp АЈНУ
- Е№НКХЉ РхОж АЈНУ
- NIC РхОж АЈНУ
- ОїЙЋПы ГзЦЎПіХЉ РхОж АЈНУ
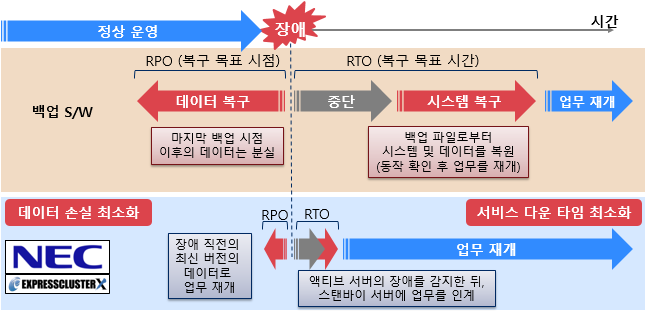
РхОж ЙпЛ§ НУ RPO Йз RTOИІ УжМвШ
RPOЁЄRTOИІ УжМвШЧЯДТ HA ХЌЗЏНКХЭ НУНКХл
ЂК РхОж ЙпЛ§ СїРќРЧ УжНХ ЙіРќРЧ ЕЅРЬХЭЗЮ НХМгЧб ОїЙЋ РчАГ
(ЕЅРЬХЭ МеНЧ УжМвШ)
ЂК РкЕП РхОж АЈСі Йз FailoverПЁ РЧЧб НХМгЧб ОїЙЋ РчАГ
(МКёНК ДйПюХИРг УжМвШ)
RPO(Recovery Point Objective) : КЙБИ ИёЧЅ НУСЁ
RTO(Recovery Time Objective) : КЙБИ ИёЧЅ НУАЃ
НХМгЧб РхОж СЖФЁПЁ РЧЧб ОїЙЋ(МКёНК) АЁПыМК ШЎКИ
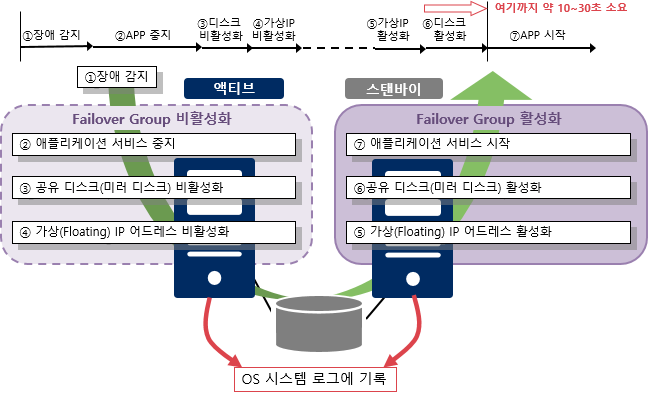
1Ка РЬГЛПЁ ОїЙЋ МКёНК Failover ПЯЗс
Ём Failover Group ДмРЇЗЮ МЙі Р§УМ
ХЌЗЏНКХЭ НУНКХлПЁМ РЮАшЧв ДыЛѓРЬ ЕЧДТ БИМКПфМв(АЁЛѓ IP ОюЕхЗЙНК,
ОжЧУИЎФЩРЬМЧ Ею)ИІ ЦфРЯПРЙі БзЗьРИЗЮ СЄРЧЧЯАэ, ЦфРЯПРЙі БзЗь ДмРЇЗЮ
МЙі FailoverАЁ РЬЗчОюС§ДЯДй.
Јч РхОж АЈСі
Јш ОжЧУИЎФЩРЬМЧ МКёНК СпСі
Јщ АјРЏ Е№НКХЉ(ЙЬЗЏ Е№НКХЉ) КёШАМКШ
Јъ АЁЛѓ(Floating) IP ОюЕхЗЙНК КёШАМКШ
Јы АЁЛѓ(Floating) IP ОюЕхЗЙНК ШАМКШ
Јь АјРЏ Е№НКХЉ(ЙЬЗЏ Е№НКХЉ) ШАМКШ
Јэ ОжЧУИЎФЩРЬМЧ МКёНК НУРл
НУНКХл ПюПЕ НУРЧ ЙЎСІСЁ ЧиАс
РхОж ДыРР, РчЧи ДыУЅ Йз АшШЙЕШ РЏСіКИМі РлОїРЧ ПјШАЧб ДыРР
Ём НУНКХл ПюПЕРЧ ДчИщ АњСІ
- НХМгЧб РхОж ДыРР Йз ОїЙЋ МКёНК ПЌМгМК КИРх
- ОїЙЋ НУАЃ ШЎДыПЁ РЧЧб МКёНК ШПРВРЧ ЧтЛѓ
- РхОж ЙпЛ§ НУ, НХМгЧб ОїЙЋ КЙБИ Йз ОїЙЋ РчАГ
- РхОж ЙпЛ§ НУ, ЕЅРЬХЭ СЄЧеМКРЛ КИРхЧЯДТ РхОж КЙБИ Йз НХМгЧб ОїЙЋ РчАГ
- АЁЛѓШ ШЏАцПЁМ ГєРК МіСиРЧ АЁПыМК ШЎКИ
- ХЌЖѓПьЕх ШЏАцПЁМ ГєРК МіСиРЧ АЁПыМК ШЎКИ
Ём NEC EXPRESSCLUSTER XЗЮ ЧиАс
- НУНКХл РхОжИІ АЈСіЧЯАэ, РкЕПРИЗЮ Failover
- ПјШАЧб Р§УМПЁ РЧЧб ОїЙЋ ПюПЕ СіМг
- АшШЙЕШ РЏСіКИМі РлОї НУПЁЕЕ ОїЙЋ ПюПЕ СіМг
- РхОж ЙпЛ§ НУПЁЕЕ RPO Йз RTOРЧ УжМвШ
- ПјАнСі ХЌЗЏНКХЭ БИМКРИЗЮ РчЧи ДыУЅ
- РхОж НУ, РкЕПРИЗЮ ПјАнСіПЁМ ОїЙЋИІ РчАГ
- АЁЛѓШ ШЏАцПЁМРЧ HA ХЌЗЏНКХЭ БтДЩ АШ
- ДйОчЧб ХЌЖѓПьЕх ШЏАцПЁМ ЕПРл ШЎРЮ ПЯЗс
- АЁЛѓ ИгНХ Йз SW РхОжПЁ ДыЧб АэАЁПыМК НЧЧі
АшШЙЕШ РЏСіКИМі РлОї НУПЁЕЕ ОїЙЋ АшМг
НКХФЙйРЬ МЙіПЁМРЧ РЏСіКИМі РлОїРИЗЮ ОїЙЋ(МКёНК) СпДм НУАЃРЛ УжМвШ
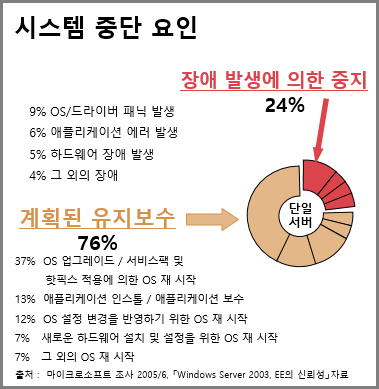
Ём НУНКХл СпДм ПфРЮ
ЂК РхОж ЙпЛ§ПЁ РЧЧб СпСі 24%
- 9% : OS/ЕхЖѓРЬЙі ЦаДа ЙпЛ§
- 6% : ОжЧУИЎФЩРЬМЧ ПЁЗЏ ЙпЛ§
- 5% : ЧЯЕхПўОю РхОж ЙпЛ§
- 4% : Бз ПмРЧ РхОж
ЂК АшШЙЕШ РЏСіКИМі 76%
- 37% : OS ОїБзЗЙРЬЕх / МКёНКЦб Йз ЧжЧШНК РћПыПЁ РЧЧб OS Рч НУРл
- 13% : ОжЧУИЎФЩРЬМЧ РЮНКХч / ОжЧУИЎФЩРЬМЧ КИМі
- 12% : OS МГСЄ КЏАцРЛ ЙнПЕЧЯБт РЇЧб OS Рч НУРл
- 7% : ЛѕЗЮПю ЧЯЕхПўОю МГФЁ Йз МГСЄРЛ РЇЧб OS Рч НУРл
- 7% : Бз ПмРЧ OS Рч НУРл
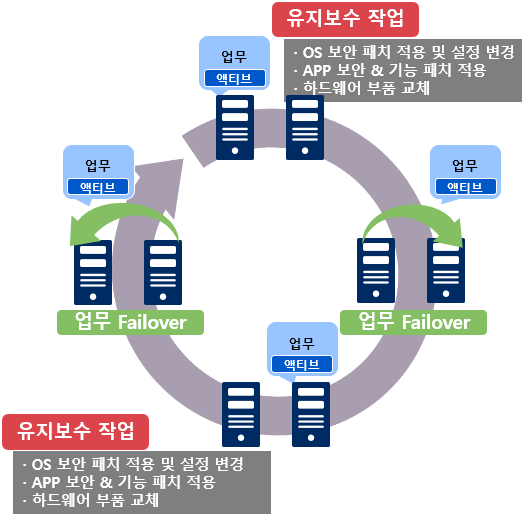
РЏСіКИМі РлОїРИЗЮ ЙпЛ§ЕЧДТ ОїЙЋ МКёНКРЧ ДйПюХИРгРЛ УжМвШ
Ём РЏСіКИМі РлОї
- OS КИОШ ЦаФЁ РћПы Йз МГСЄ КЏАц
- APP КИОШ & БтДЩ ЦаФЁ РћПы
- ЧЯЕхПўОю КЮЧА БГУМ
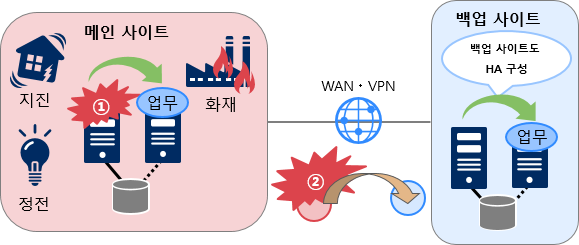
ПјАнСі ХЌЗЏНКХЭ БИМКПЁ РЧЧб РчЧи ДыУЅ
СіСј, ШЋМі, ШРч, СЄРќ ЕюРЧ РчЧи ЙпЛ§НУПЁЕЕ ОїЙЋ(МКёНК)ИІ СіМг
ЈчЧЯЕхПўОю / МвЧСЦЎПўОю РхОжДТ ИоРЮ ЛчРЬЦЎ ГЛПЁМ Failover УГИЎ
ЈшИоРЮ ЛчРЬЦЎ РќУМ РхОж ЙпЛ§ НУ, ЙщОї ЛчРЬЦЎЗЮ Failover УГИЎ
ХЌЖѓПьЕх ШЏАцПЁМ ГєРК МіСиРЧ АЁПыМК ШЎКИ
ХЌЖѓПьЕх ШЏАцЕЕ NEC EXPRESSCLUSTER XЗЮ БИМКЧЯПЉ АЁПыМК ЧтЛѓ
Ём ХЌЖѓПьЕх ШЏАцРЧ АњСІ
(A) ХЌЖѓПьЕх ШЏАцПЁМ ПЯКЎЧб ОїЙЋ(МКёНК) АЁПыМКРЛ РЏСіЧЯБт РЇЧб ЙцЙ§РК
РЏРњАЁ БИЧіЧиОп ЧбДй.(ЕЅРЬХЭ АјРЏ / Failover Р§Тї Ею)
(B) ОжЧУИЎФЩРЬМЧ(ОїЙЋ МКёНК)РЧ АЁПыМКРК ЛчПыРк УЅРгЧЯПЁ МГСЄРЬ ЧЪПф
(C) ХЌЖѓПьЕх КЅДѕ РкУМРћРИЗЮ ЙпЛ§ЕЧДТ РхОж ЕЕ АэЗСЧиОп ЧбДй.
Ём NEC EXPRESSCLUSTER XЗЮ ЧиАс
(A) РхОж ЙпЛ§ НУ, ОїЙЋ(МКёНК)ИІ РкЕПРИЗЮ FailoverЧЯПЉ, Availability ZoneАЃРЧ
ЕЅРЬХЭ АјРЏИІ НБАд БИЧіЧбДй.
(B) ОжЧУИЎФЩРЬМЧРЧ ММКЮ И№ДЯХЭИЕРЛ ХыЧи РхОж ЙпЛ§ПЁ РЧЧб ПЕЧтРЛ УжМвШЧбДй.
(C) ХЌЖѓПьЕх КЅДѕРЧ РкУМ РхОж ЙпЛ§ НУРЧ ПЕЧтРЛ УжМвШЧбДй.
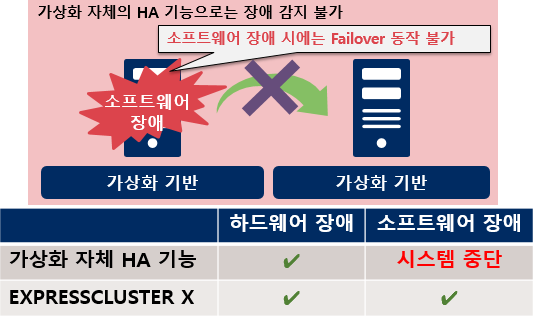
АЁЛѓШ ШЏАцПЁМ ГєРК МіСиРЧ АЁПыМК ШЎКИ
АЁЛѓШ РкУМРЧ HA БтДЩРИЗЮ АЈСіЧв Мі ОјДТ МвЧСЦЎПўОю РхОж АЈСі Йз Failover
ЂК НХМгЧЯАэ СЄШЎЧЯАд ОжЧУИЎФЩРЬМЧ Йз ЧЯЕхПўОюРЧ РхОжИІ АЈСіЧЯАэ,
РкЕПРИЗЮ КЙБИ РлОї(Failover)РЛ НЧНУЧЯПЉ ОїЙЋИІ СіМг
ЂК АЁЛѓШРЧ РкУМ HA БтДЩКИДй ДѕПэ КќИЃАд Failover НЧНУ
ЂК АЁЛѓШ БтЙнРЧ Live Migration БтДЩАњ ПЌАшЧб ЕПРлРЬ АЁДЩ
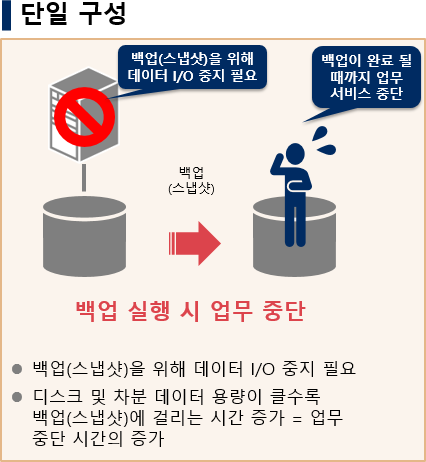
РЏПЌЧб ЙщОї(НКГРМІ) НУНКХл ПюПЕ
ЙщОї НЧЧр НУПЁ ОїЙЋ МКёНКПЁ ЙЬФЁДТ ПЕЧтРЛ УжМвШ
Ём ДмРЯ БИМК
- ЙщОї НЧЧр НУ ОїЙЋ СпДм
- ЙщОї(НКГРМІ)РЛ РЇЧи ЕЅРЬХЭ I/O СпСі ЧЪПф
- Е№НКХЉ Йз ТїКа ЕЅРЬХЭ ПыЗЎРЬ ХЌМіЗЯ ЙщОї(НКГРМІ)ПЁ АЩИЎДТ НУАЃ СѕАЁ
= ОїЙЋ СпДм НУАЃРЧ СѕАЁ
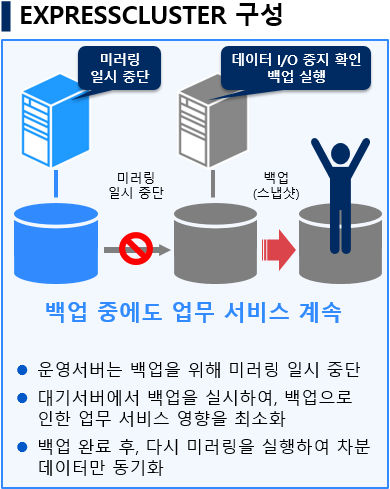
Ём NEC EXPRESSCLUSTER БИМК
- ЙщОї СпПЁЕЕ ОїЙЋ МКёНК АшМг
- ПюПЕМЙіДТ ЙщОїРЛ РЇЧи ЙЬЗЏИЕ РЯНУ СпДм
- ДыБтМЙіПЁМ ЙщОїРЛ НЧНУЧЯПЉ, ЙщОїРИЗЮ РЮЧб ОїЙЋ МКёНК ПЕЧтРЛ УжМвШ
- ЙщОї ПЯЗс ШФ, ДйНУ ЙЬЗЏИЕРЛ НЧЧрЧЯПЉ ТїКа ЕЅРЬХЭИИ ЕПБтШ
NEC EXPRESSCLUSTER X МвАГ РкЗс
NEC EXPRESSCLUSTER X СІЧА МвАГ РкЗс (ФЋХЛЗЮБз)
ЁЁЦФРЯИэ : expresscluster_introduction_fhubis.pdf
NEC EXPRESSCLUSTER X 4.1 МвАГ РкЗс
ЁЁЦФРЯИэ : ecx41-product-introduction_fhubis.pdf
 ЁЁЦФРЯИэ : expresscluster_introduction_fhubis.pdf
ЁЁЦФРЯИэ : expresscluster_introduction_fhubis.pdf